
По сообщению AWS Machine Learning Blog, платформа машинного обучения Amazon SageMaker Canvas получила поддержку бессерверного развертывания моделей через Amazon SageMaker Serverless Inference. Это решение устраняет одну из ключевых проблем для бизнес-пользователей — сложность вывода моделей в продакшен без глубоких технических знаний.
Проблема развертывания ML-моделей
Создание моделей машинного обучения в Amazon SageMaker Canvas уже давно упрощено благодаря no-code интерфейсу, но развертывание этих моделей в production оставалось сложной задачей, требующей знаний DevOps и управления инфраструктурой. Amazon SageMaker Serverless Inference решает эту проблему, автоматически масштабируя инфраструктуру в зависимости от нагрузки и устраняя необходимость управления серверами.
Рабочий процесс развертывания
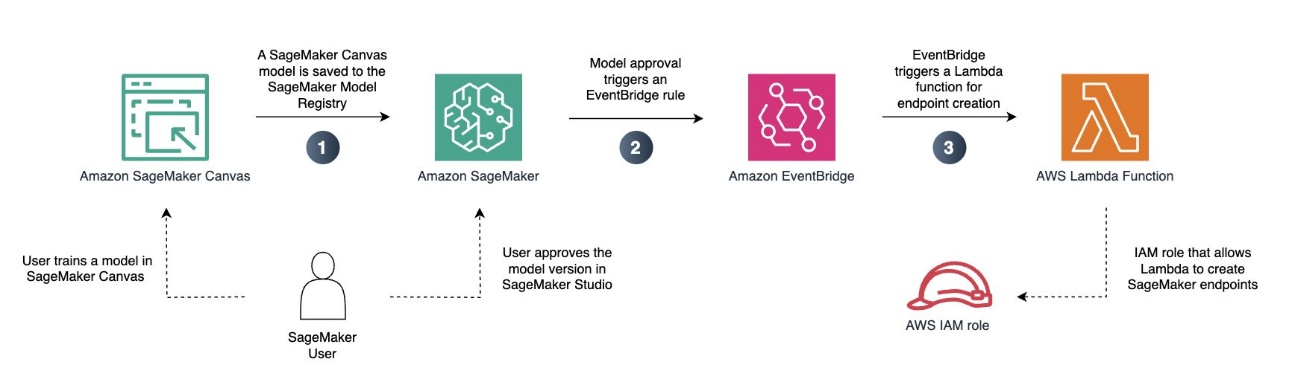
Процесс бессерверного развертывания модели из SageMaker Canvas включает четыре основных шага:
- Добавление обученной модели в Amazon SageMaker Model Registry
- Создание новой модели SageMaker с правильной конфигурацией
- Создание конфигурации бессерверной конечной точки
- Развертывание бессерверной конечной точки с созданной моделью и конфигурацией
Подготовка модели к развертыванию
Для начала процесса необходимо иметь доступ к Amazon Simple Storage Service (Amazon S3) и Amazon SageMaker AI. Также требуется предварительно обученная модель регрессии или классификации. В примере используется классификационная модель, обученная на датасете canvas-sample-shipping-logs.csv.
Сохраняем модель в реестре моделей
Процесс начинается с сохранения модели в SageMaker Model Registry:
- На консоли SageMaker AI выбираем Studio для запуска Amazon SageMaker Studio
- В интерфейсе SageMaker Studio запускаем SageMaker Canvas, который открывается в новой вкладке
- Находим модель и версию модели, которую хотим развернуть на бессерверной конечной точке
- В меню опций (три вертикальные точки) выбираем Add to Model Registry
Утверждение модели для развертывания
После добавления модели в Model Registry необходимо:
- В интерфейсе SageMaker Studio выбрать Models в панели навигации
- Выбрать версию модели для развертывания и обновить статус на Approved, выбрав статус развертывания
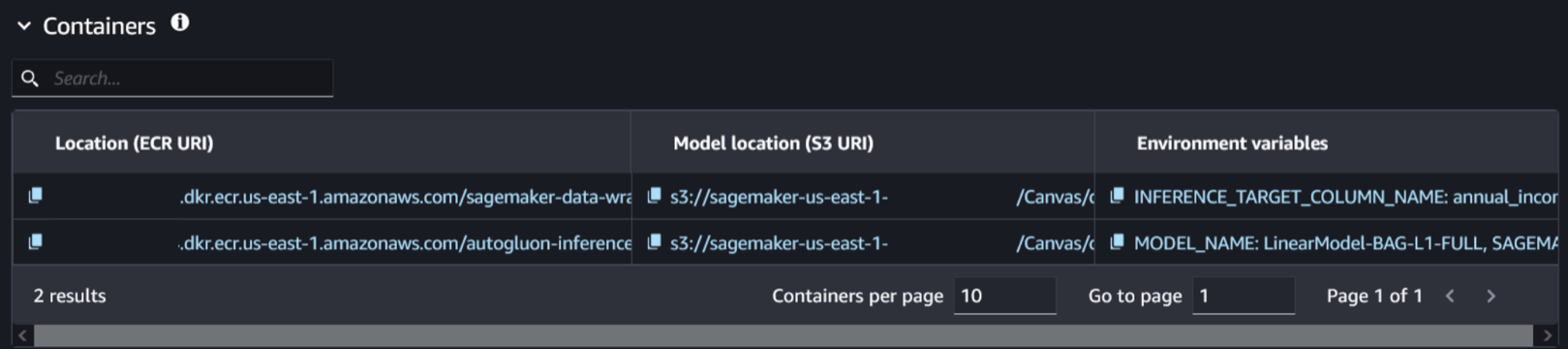
- Выбрать версию модели и перейти на вкладку Deploy, где находится информация о модели и связанном контейнере
- Выбрать контейнер и расположение модели, связанные с обученной моделью. Их можно идентифицировать по наличию переменной окружения
SAGEMAKER_DEFAULT_INVOCATIONS_ACCEPT
Создание новой модели
Завершающий этап — создание новой модели:
- Не закрывая вкладку SageMaker Studio, открываем новую вкладку и заходим в консоль SageMaker AI
- Выбираем Models в разделе Inference и нажимаем Create model
- Присваиваем имя модели
- Оставляем опцию ввода контейнера как Provide model artifacts and inference image location и используем тип
CompressedModel - Вводим URI Amazon Elastic Container Registry (Amazon ECR), URI Amazon S3 и переменные окружения, найденные на предыдущем шаге
Наконец-то AWS закрывает один из самых болезненных пробелов в своем ML-стеке. No-code создание моделей было красивой фичей, но без нормального развертывания оставалось скорее демо-версией для презентаций. Теперь бизнес-аналитики действительно могут самостоятельно доводить проекты до продакшена — это серьезный шаг к демократизации ML. Особенно ценно, что решение работает с переменными нагрузками, что идеально для стартапов и MVP.
Этот подход особенно эффективен для рабочих нагрузок с переменными паттернами трафика и периодами простоя, где традиционное развертывание было бы неоправданно дорогим.