
Компания Cerebras, известная своими гигантскими специализированными чипами для ИИ, представила необычную для себя разработку. Речь идет о новой архитектуре нейронной сети — Implicit Chain Transformer (ICT). Цель — решить фундаментальную проблему современных языковых моделей: их «беспамятность».
Проблема статического контекста
Стандартные Transformer-декодеры, лежащие в основе ChatGPT и других LLM, работают по принципу «живи настоящим». Для генерации каждого нового токена модель должна заново обработать всю предыдущую последовательность через механизм внимания. Она не может просто «запомнить» промежуточное состояние, например, текущую сумму в арифметической задаче. Этот представительский бутылочный горлышко делает модели хрупкими в задачах, требующих поддержания и точного обновления состояния: сложение по модулю, обход графа или последовательные рассуждения.
Решение: горизонтальный поток намерения
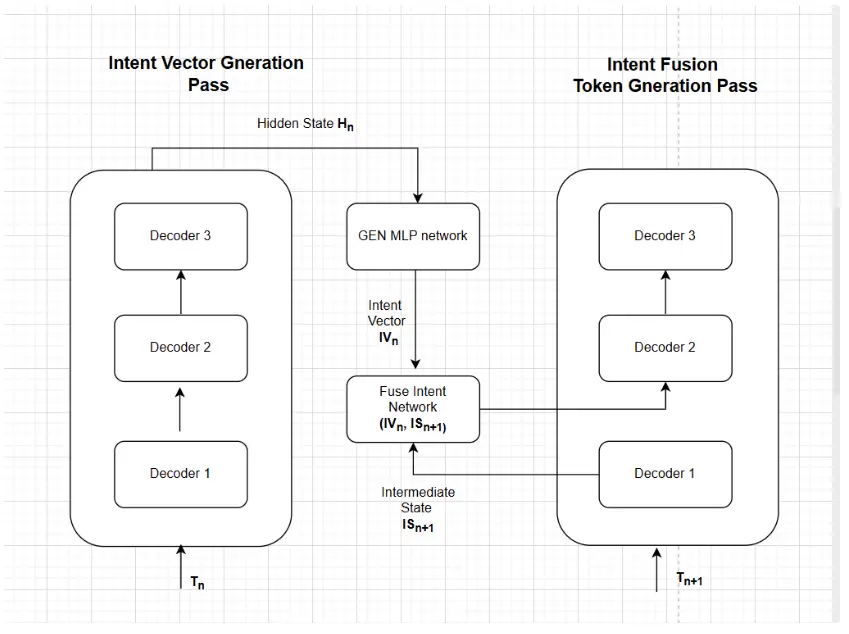
Implicit Chain Transformer вводит в архитектуру новый элемент — «вектор намерения» (Intent Vector). Это обучаемый латентный вектор, который передается горизонтально от одного токена к другому, выступая в роли сжатой оперативной памяти. Модель «записывает» текущее логическое состояние в этот вектор и передает его дальше, сохраняя контекст без необходимости постоянно пересчитывать историю.
Исследователи из Cerebras предложили две стратегии для этой передачи состояния:
- Авторегрессивная передача (Dense): Состояние обновляется на каждом шаге генерации токена. Вектор из последнего слоя токена t внедряется в ранние слои токена t+1, создавая постоянный «поток памяти».
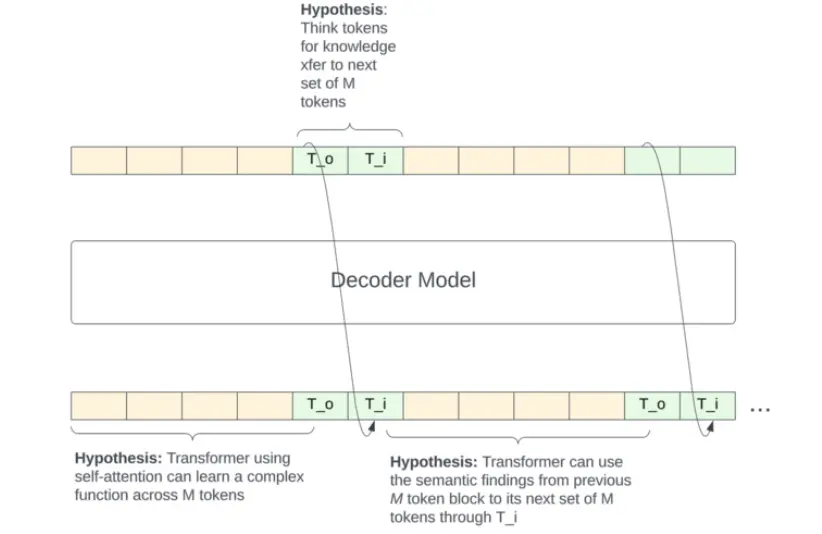
- Периодическая передача (Sparse): Состояние обновляется только в специальных точках, обозначенных токенами <THINK>. Это заставляет модель использовать их как семантические контрольные точки для агрегации контекста, что потенциально выгоднее для оптимизации инференса.
Как обойти проблему обучения рекуррентных сетей
Ключевая сложность при внедрении рекуррентности — потеря эффективности параллельного обучения, характерной для Transformers. Чтобы не возвращаться к медленному последовательному обучению RNN, Cerebras использует метод «итеративной латентной обратной связи» (Iterative Latent Feedback).
- Параллельный проход: Вся последовательность обрабатывается стандартным образом для генерации начальных латентных представлений.
- Инъекция обратной связи: Вектор из последнего слоя первого прохода проектируется через MLP и внедряется как вход «намерения» в ранние слои.
- Уточняющий проход: Выполняется второй прямой проход с этим объединенным контекстом для вычисления итогового лосса.
Это вводит фиксированные вычислительные накладные расходы (дополнительные проходы), но стоимость остается константной независимо от длины последовательности, сохраняя O(1) сложность обучения.
Ранние результаты и архитектура
Для тестирования использовалась модель в стиле GPT-2. Модификации ICT добавлялись поверх базовой архитектуры. Ключевые компоненты:
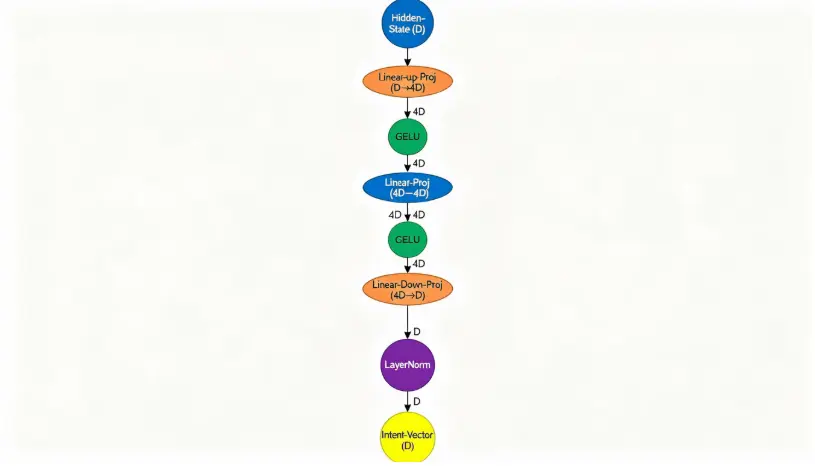
- GenMLP: Специальная MLP-сеть, которая считывает выход промежуточного или финального слоя LLM и генерирует вектор намерения.
- Fuse-Intent сеть: Объединяет выход первого декодерного слоя с вектором намерения.
Результаты на задачах «Сложение по модулю» и «Обход графа» показали, что обе вариации ICT (Dense и Sparse) значительно и стабильно превосходят базовую модель.
- Базовая модель демонстрирует либо катастрофический коллапс точности после определенной глубины контекста, либо плавную деградацию.
- ICT-модели сохраняют высокую точность на гораздо более длинных последовательностях, подтверждая гипотезу о том, что передача латентного вектора предотвращает необходимость перевычисления состояния.
Идея добавить в Transformer «память» — не нова. Но подход Cerebras интересен своей прагматичностью и попыткой сохранить священную корову параллельного обучения. Пока что это фундаментальное исследование на игрушечных задачах, но оно бьет прямо в больное место современных LLM — их неспособность к надежному, последовательному рассуждению без подсказок типа Chain-of-Thought. Если эту архитектуру удастся масштабировать до уровня больших моделей, это может стать шагом к созданию ИИ, который действительно «думает», а не просто статистически угадывает следующее слово. Впрочем, расстояние от лабораторного сложения по модулю 97 до осмысленного диалога — все еще огромно.
Работа представляет собой раннее исследование, но направление многообещающее. Вместо того чтобы заставлять модель «проговаривать» свои рассуждения вслух через CoT, что увеличивает задержку и стоимость инференса, ICT пытается сделать рассуждение неявным и внутренним. Это соответствует более общей цели Cerebras — делать вычисления ИИ эффективнее не только на уровне железа, но и на уровне архитектуры.
По материалам Cerebras.